
ความหมายของ Big Data
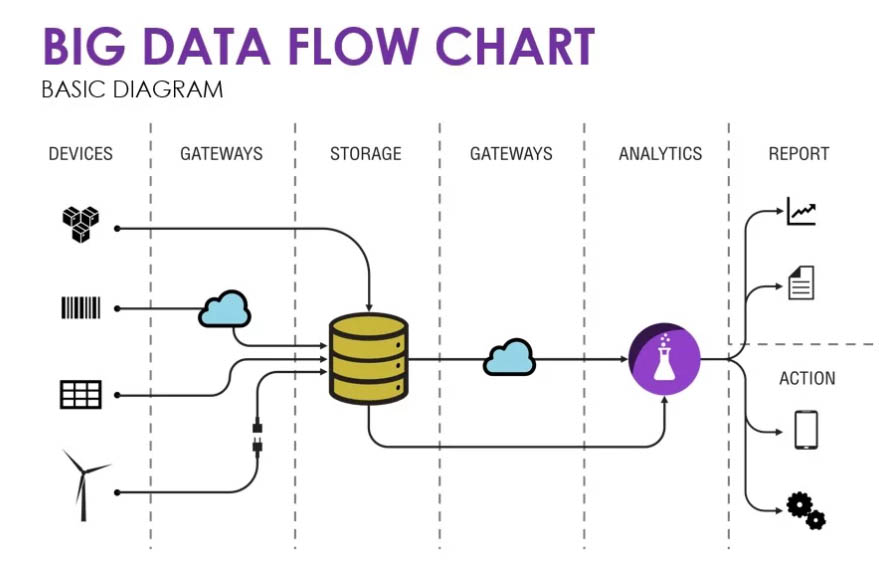
จากภาพ จะเห็นได้ว่า องค์ประกอบของระบบ Data แบ่งออกเป็น 5 ส่วนด้วยกัน ได้แก่
1. Data Source แหล่งที่มาของข้อมูล
ซึ่งถือได้ว่า เป็นต้นน้ำ เป็นแหล่งกำเนิดของข้อมูล อาจจะเป็นระบบ โปรแกรม หรือจะเป็นมนุษย์เรา ที่สร้างให้เกิดข้อมูลขึ้นมา ทั้งนี้ เมื่อได้ชื่อว่าเป็น Big Data แล้ว ข้อมูลต่างๆ มักจะมาจากแหล่งข้อมูลที่หลากหลาย นำพามาซึ่งความยากลำบากในการจัดการโครงสร้าง หรือจัดเตรียมให้ข้อมูลที่นำมารวมกันนั้น มีความพร้อมใช้ต่อไป
2. Gateway ช่องทางการเชื่อมโยงข้อมูล
การเชื่อมโยงข้อมูล เป็นส่วนที่สำคัญมาก และเป็นปัญหาใหญ่ในการทำ Big Data Project ต้องอาศัยทักษะของ Data Engineer ทั้งการเขียนโปรแกรมเอง และใช้เครื่องมือที่มีอยู่มากมาย ทั้งนี้การจะออกแบบช่องทางการเชื่อมโยงข้อมูลได้อย่างสมบูรณ์แบบ จำเป็นต้องทราบก่อนว่า จะนำข้อมูลใดไปทำอะไรต่อบ้าง มิเช่นนั้น การสร้างช่องทางการเชื่อมที่ไม่มีเป้าหมาย ก็อาจเป็นการเสียเวลาโดยเปล่าประโยชน์
3. Storage แหล่งเก็บข้อมูล
แหล่งเก็บนี้ ไม่ใช่แค่การเก็บข้อมูลจากแหล่งข้อมูล แต่เป็นการเก็บข้อมูลจากแหล่งข้อมูลหลายๆ แหล่ง เอามาไว้เพื่อรอการใช้งาน ซึ่งอาจจะเป็นที่พักข้อมูลให้พร้อมใช้ หรือจะเป็นแหล่งเก็บข้อมูลในอดีตก็เป็นได้
4. Analytics การวิเคราะห์ข้อมูล
ส่วนนี้เป็นหน้าที่หลักของ Data Scientist ซึ่งแบ่งงานออกเป็น 2 ลักษณะ คือ การวิเคราะห์เบื้องต้น โดยการใช้วิธีทางสถิติ หรือจะเป็นการวิเคราะห์เชิงลึกโดยการสร้าง Model แบบต่างๆ รวมไปถึงการใช้ Machine Learning เพื่อให้ได้ผลลัพธ์เฉพาะจงเจาะในแต่ละปัญหา และแต่ละชุดข้อมูล
5. Result/Action การใช้ผลการวิเคราะห์ข้อมูล
ผลลัพธ์ที่ได้จากการวิเคราะห์สามารถนำไปใช้งานได้ 2 รูปแบบ คือ ออกเป็นรายงาน เพื่อให้ Data Analyst นำผลลัพธ์ที่ได้ไปใช้กับงานทางธุรกิจต่อไป หรือจะเป็นการนำไปกระทำเลยโดยที่ไม่ต้องมี “มนุษย์” คอยตรวจสอบ ซึ่งจำเป็นต้องมีการเขียนโปรแกรมเพิ่ม เพื่อให้มีการกระทำออกไป ที่เรียกว่า Artificial Intelligence (AI)
ลักษณะที่สำคัญของ Big Data
Big data ที่มีคุณภาพสูงควรมีลักษณะพื้นฐานอยู่ 6 ประการหลักๆ (6 Vs) ดังนี้
1. ปริมาณ (Volume) หมายถึง ปริมาณของข้อมูลควรมีจำนวนมากพอ ทำให้เมื่อนำมาวิเคราะห์แล้วจะได้ insights ที่ตรงกับความเป็นจริง เช่น การที่เรามีข้อมูลอายุ เพศ ของลูกค้าส่วนใหญ่ ทำให้เราสามารถหา demographic profile ทั่วไปของลูกค้าที่ถูกต้องได้ ถ้าเรามีข้อมูลลูกค้าแค่ส่วนน้อย ค่าที่ประมาณออกมาอาจจะไม่ตรงกับความเป็นจริง
2. ความหลากหลาย (Variety) หมายถึง รูปแบบของข้อมูลควรหลากหลายแตกต่างกันออกไป ทั้งแบบโครงสร้าง, กึ่งโครงสร้าง, ไม่มีโครงสร้าง ทำให้เราสามารถนำมาวิเคราะห์ประกอบกัน จนได้ได้ insights ครบถ้วน
3. ความเร็ว (Velocity) หมายถึง คุณลักษณะข้อมูลที่ถูกสร้างขึ้นอย่างรวดเร็วต่อเนื่องและทันเหตุการณ์ ทำให้เราสามารถวิเคราะห์ข้อมูลแบบ real-time นำผลลัพธ์มาทำการตัดสินใจและตอบสนองได้อย่างทันท่วงที เช่น ข้อมูล GPS ที่ใช้ติดตามตำแหน่งของรถ อาจจะนำมาวิเคราะห์โอกาสที่ทำให้เกิดอุบัติเหตุ และออกแบบระบบป้องกันอุบัติเหตุได้
4. ความถูกต้อง (Veracity) หมายถึง มีความน่าเชื่อถือของแหล่งที่มาข้อมูลและความถูกต้องของชุดข้อมูล มีกระบวนการในการตรวจสอบและยืนยันความถูกต้องของข้อมูล ซึ่งมีความเกี่ยวเนื่องโดยตรงกับผลลัพท์การวิเคราะห์ข้อมูล
5. คุณค่า (Value) หมายถึง ข้อมูลมีประโยชน์และมีความสัมพันธ์ในเชิงธุรกิจ ซึ่งต้องเข้าใจก่อนว่าไม่ใช่ทุกข้อมูลจะมีประโยชน์ในการเก็บและวิเคราะห์ ข้อมูลที่มีประโยชน์จะต้องเกี่ยวข้องกับวัตถุประสงค์ทางธุรกิจ เช่นถ้าต้องการเพิ่มขีดความสามารถในการแข่งขันในตลาดของผลิตภัณฑ์ที่ขาย ข้อมูลที่มีประโยชน์ที่สุดน่าจะเป็นข้อมูลผลิตภัณฑ์ของคู่แข่ง
6. ความแปรผันได้ (Variability) หมายถึง ข้อมูลสามารถในการเปลี่ยนแปลงรูปแบบไปตามการใช้งาน หรือสามารถคิดวิเคราะห์ได้จากหลายแง่มุม และรูปแบบในการจัดเก็บข้อมูลก็อาจจะต่างกันออกไปในแต่ละแหล่งของข้อมูล
คุณลักษณะเหล่านี้ทำให้การจัดการ Big Data เป็นเรื่องยาก แต่ในขณะเดียวกันก็เป็นโอกาสให้องค์กรสร้างความได้เปรียบเหนือคู่แข่งด้วยการพัฒนาขีดความสามารถในการวิเคราะห์ข้อมูล
วิวัฒนาการของ Big Data
ถึงแม้ว่าแนวคิดเรื่องข้อมูลขนาดใหญ่หรือ Big Data จะเป็นของใหม่และมีการเริ่มทำกันในไม่กี่ปีมานี้เอง แต่ต้นกำเนิดของชุดข้อมูลขนาดใหญ่ได้มีการริเริ่มสร้างมาตั้งแต่ยุค 60 และในยุค 70 โลกของข้อมูลก็ได้เริ่มต้น และได้พัฒนาศูนย์ข้อมูลแห่งแรกขึ้น และทำการพัฒนาฐานข้อมูลเชิงสัมพันธ์ขึ้นมา
ประมาณปี 2005 เริ่มได้มีการตะหนักถึงข้อมูลปริมาณมากที่ผู้คนได้สร้างข้นมาผ่านสื่ออนไลน์ เช่น เฟสบุ๊ค ยูทูป และสื่ออนไลน์แบบอื่นๆ Hadoop เป็นโอเพ่นซอร์สเฟรมเวิร์คที่ถูกสร้างขึ้นมาในช่วงเวลาเดียวกันให้เป็นที่เก็บและวิเคราะห์ข้อมูลขนาดใหญ่ และในช่วงเวลาเดียวกัน NoSQL ได้ก็เริ่มขึ้นและได้รับความนิยมมากขึ้น
การพัฒนาโอเพนซอร์สเฟรมเวิร์ค เช่น Hadoop (และเมื่อเร็ว ๆ นี้ก็มี Spark) มีความสำคัญต่อการเติบโตของข้อมูลขนาดใหญ่ เนื่องจากทำให้ข้อมูลขนาดใหญ่ทำงานได้ง่าย และประหยัดกว่า ในช่วงหลายปีที่ผ่านมาปริมาณข้อมูลขนาดใหญ่ได้เพิ่มขึ้นอย่างรวดเร็ว ผู้คนยังคงสร้างข้อมูลจำนวนมาก ซึ่งไม่ใช่แค่มนุษย์ที่ทำมันขึ้นมา
การพัฒนาการของ IOT (Internet of Thing) ซึ่งเป็นเครื่องมืออุปกรณ์ที่เชื่อมต่อกับอินเตอร์เนตก็ทำการเก็บและรวบรวมข้อมูลซึ่งอาจเป็นเรื่องที่เกี่ยวกับพฤติกรรมการใช้งานของลูกค้า ประสิทธิภาพของสินค้า หรือการเรียนรู้ของเครื่องจักรพวกนี้ล้วนทำให้มีข้อมูลขนาดใหญ่
แม้ว่ายุคของข้อมูลขนาดใหญ่ Big Data มาถึงและได้เริ่มต้นแล้ว แต่มันก็ยังเป็นเพียงแต่ช่วงแรกๆ และระบบระบบคลาวด์คอมพิวติ้งก็ได้ขยายความเป็นไปได้มากขึ้น คลาวด์มีความสามารถในการในการใช้งานได้อย่างยืดหยุ่นได้
ก่อนที่ธุรกิจจะสามารถนำ Big Data มาใช้งานได้ พวกเขาควรพิจารณาว่าข้อมูลจะไหลเวียนไปยังสถานที่ แหล่งที่มา ระบบ เจ้าของ และผู้ใช้จำนวนมากได้อย่างไร มีห้าขั้นตอนสำคัญในการจัดการ “โครงสร้างข้อมูล” ขนาดใหญ่นี้ ซึ่งรวมถึงข้อมูลแบบดั้งเดิม ข้อมูลที่มีโครงสร้าง และข้อมูลที่ไม่มีโครงสร้างและกึ่งมีโครงสร้าง:
1) กำหนดกลยุทธ์เกี่ยวกับข้อมูลขนาดใหญ่
ในระดับสูง กลยุทธ์ข้อมูลขนาดใหญ่เป็นแผนที่ออกแบบมาเพื่อช่วยคุณในการกำกับดูแลและปรับปรุงวิธีที่คุณได้รับ จัดเก็บ จัดการ แบ่งปัน และใช้ข้อมูลภายในและภายนอกองค์กรของคุณ กลยุทธ์ข้อมูลขนาดใหญ่ช่วยปูทางไปสู่ความสำเร็จทางธุรกิจท่ามกลางข้อมูลจำนวนมาก เมื่อพัฒนากลยุทธ์ สิ่งสำคัญคือต้องพิจารณาเป้าหมายทางธุรกิจและเทคโนโลยี –ในปัจจุบันและอนาคต – และโครงการริเริ่ม การปฏิบัติกับข้อมูลขนาดใหญ่มีความจำเป็นเช่นทรัพย์สินทางธุรกิจที่มีค่าอื่นๆ แทนที่จะเป็นเพียงผลพลอยได้ของแอปพลิเคชัน
2) รู้แหล่งที่มาของข้อมูลขนาดใหญ่
- กระแสข้อมูลมาจาก Internet of Things (IoT) และอุปกรณ์ที่เชื่อมต่ออื่นๆ ที่ไหลเข้าสู่ระบบไอทีจากอุปกรณ์สวมใส่ รถยนต์อัจฉริยะ อุปกรณ์ทางการแพทย์ อุปกรณ์อุตสาหกรรม และอื่นๆ คุณสามารถวิเคราะห์ข้อมูลขนาดใหญ่นี้ได้เมื่อมาถึง รวมถึงตัดสินใจเลือกข้อมูลที่จะเก็บหรือไม่เก็บ และข้อมูลใดที่ต้องมีการวิเคราะห์เพิ่มเติม
- โซเชียลมีเดีย ข้อมูลเกิดจากการโต้ตอบบน Facebook, YouTube, Instagram ฯลฯ ซึ่งรวมถึงข้อมูลขนาดใหญ่จำนวนมหาศาลในรูปแบบของภาพ วิดีโอ คำพูด ข้อความ และเสียง – มีประโยชน์สำหรับฟังก์ชั่นการตลาด การขาย และการสนับสนุน ข้อมูลนี้มักจะอยู่ในรูปแบบที่ไม่มีโครงสร้างหรือกึ่งโครงสร้าง
ดังนั้นจึงเป็นความท้าทายในแบบเฉพาะ สำหรับการบริโภค และการวิเคราะห์ - ข้อมูลที่เปิดเผยต่อสาธารณชน มาจากแหล่งข้อมูลแบบเปิดขนาดใหญ่เช่น data.gov ของรัฐบาลสหรัฐ, CIA World Factbook หรือพอร์ทัลข้อมูลแบบเปิดของสหภาพยุโรป
- ข้อมูลขนาดใหญ่อื่นๆ อาจมาจากพื้นที่เก็บข้อมูลส่วนกลาง แหล่งข้อมูลบนระบบคลาวด์ ซัพพลายเออร์ และลูกค้า
3) การเข้าถึง จัดการ และจัดเก็บข้อมูลขนาดใหญ่
ระบบคอมพิวเตอร์สมัยใหม่มีความเร็ว พลัง และความยืดหยุ่นที่จำเป็นในการเข้าถึงข้อมูลจำนวนมหาศาลและประเภทของข้อมูลขนาดใหญ่ได้อย่างรวดเร็ว นอกเหนือจากการเข้าถึงที่เชื่อถือได้แล้ว บริษัทต่างๆยังต้องมีวิธีในการรวมข้อมูล รับประกันคุณภาพของข้อมูล การจัดระเบียบข้อมูลและการจัดเก็บ และการเตรียมข้อมูล
4) การวิเคราะห์ข้อมูลขนาดใหญ่
ด้วยเทคโนโลยีที่มีประสิทธิภาพสูง เช่น Grid Computing (การประมวลผลแบบกริด) หรือการวิเคราะห์ในหน่วยความจำ องค์กรต่างๆ จึงสามารถเลือกที่จะใช้ข้อมูลขนาดใหญ่ทั้งหมดของพวกเขามาทำการวิเคราะห์ได้ แต่ไม่ว่าจะใช้วิธีใด การวิเคราหะ์ข้อมูลขนาดใหญ่เป็นวิธีที่บริษัทต่างๆ ได้รับมูลค่าและข้อมูลเชิงลึกจากข้อมูล ปัจจุบันข้อมูลขนาดใหญ่ป้อนข้อมูลเข้าสู่ระบบการวิเคราะห์ที่มีความก้าวหน้าที่สูงขึ้น เช่น ปัญญาประดิษฐ์
5) ตัดสินใจอย่างชาญฉลาดและใช้ข้อมูลช่วย
ข้อมูลที่ได้รับการจัดการและมีความน่าเชื่อถือนำไปสู่การวิเคราะห์ที่น่าเชื่อถือและการตัดสินใจที่น่าเชื่อถือ เพื่อให้สามารถแข่งขันได้ ธุรกิจต่างๆ จำเป็นต้องได้รับประโยชน์สูงสุดจากข้อมูลขนาดใหญ่และดำเนินงานบนพื้นฐานข้อมูล – ทำการตัดสินใจบนพื้นฐานหลักฐานที่นำเสนอโดยข้อมูลขนาดใหญ่ไม่ใช่ตามสัญชาตญาณของผู้บริหาร การขับเคลื่อนด้วยข้อมูลมีประโยชน์ที่ชัดเจน





